AKS Networking considerations - part 2
Hi all!
It’s here, part 2 of the AKS network considertions series. Remember, in part 1 we talked mostly of the control plane. Which needed some specific Azure PaaS network concepts.
Today, we move on to talk about the worker plane, mostly, but also some other considerations in the use of subnets for AKS.
Let’s get started
1. Network considerations for the worker plane
When talking about Kubernetes, we have to consider how the pods are talking to each other, or to the outside world.
That’s where comes the CNI topic. CNI stands for Container Network Interface and is the part which allows for different providers (Network providers) to developpe their solution and plug it to Kubernetes. There are a lot of CNI solutions, in the Kubernetes project. But from an AKS point of view, for a long time, we had only 2 options:
- Kubenet
- Azure CNI
Let’s start with Kubenet
1.1. Kubenet
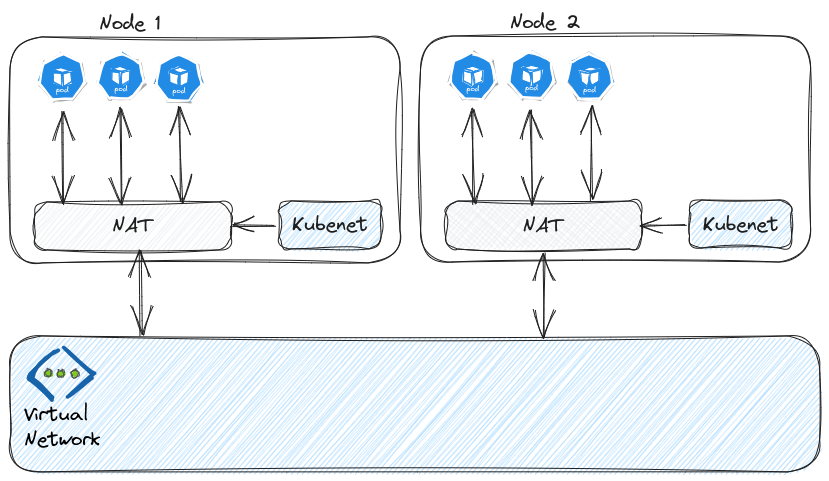
Kubenet is the default network configuration for the worker plane, and I guess that’s because there is less planning to do from an network perspective. AKS with kubenet relies on a NAT based technology. Pods have their own IP range, hidden from the Virtual Network range. The positive impact of this is that we only have to plan for the nodes IP consumption. We can for instance plan for a /26 for the AKS subnet and we’ll have up to 59 nodes for our cluster.
What should be planned are the ranges for the pods and for the kubernetes service. But there is a default value for both ranges
| Pod CIDR default value | Service CIDR default value |
|---|---|
10.244.0.0/16 |
10.0.0.0/16 |
A cluster with kubenet will display kubenet in the network plugin value and a value for both pod cidr and service cidr:
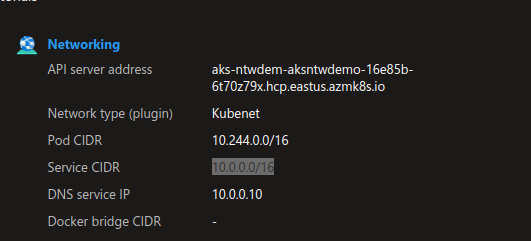
Note that those range are private from an Azure standpoint. Which means tht we can re-use those on other clusters.
Now let’s talk about limitations. Not all feature for AKS are available with kubenet, even if it got better with time. It is not possible to mutualized the AKS subnet for multiple clusters with kubenet. The rule is One cluster / 1 subnet Second, and maybe the most important point, there is an the added latency due to the additional hop for flows when reaching a workload inside the cluster. This additioal latency is not easy to evaluate but seems sufficiant so that Microsoft does not recommand kubenet for production environment.
Looking at the network flows, Those go first through one of the node and then to the pods. To do so, a User defined route (UDR) associated to the aks subnet is required. This UDR is managed and updated by the control plane and is define next hops for chunks of the Pod CIDR, associating a /24 from the range to each nodes:
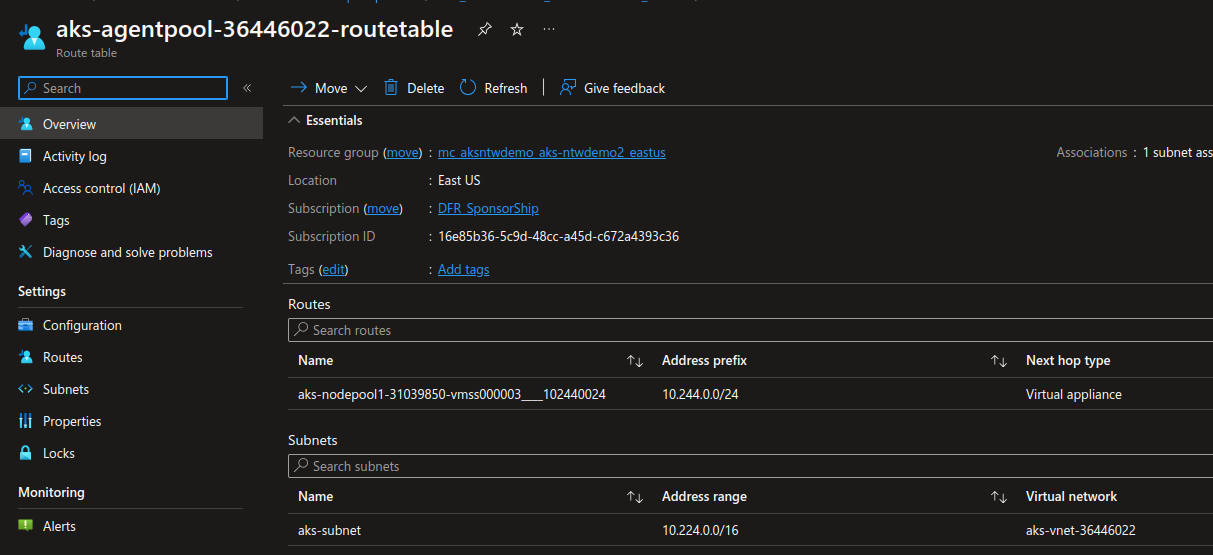
Additional nodes would be declared with additional routes.
Let’s note also the non-compatibility of kubenet with Windows Node pools. IMHO, Windows based containers are not necessarily a good idea, but that’s just my 2 cents on the topic.
If we want better performances or Windows container, then we need to consider Azure CNI.
1.2. Azure CNI
A cluster configured with Azure CNI will NOT display a range for the pod CIDR.
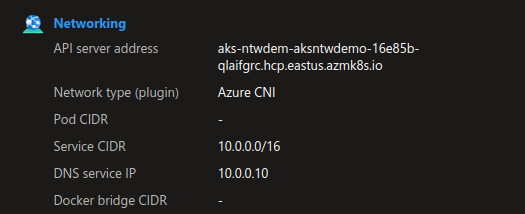
That’s because of the nature of the CNI which offers a better integration with the virtual network.
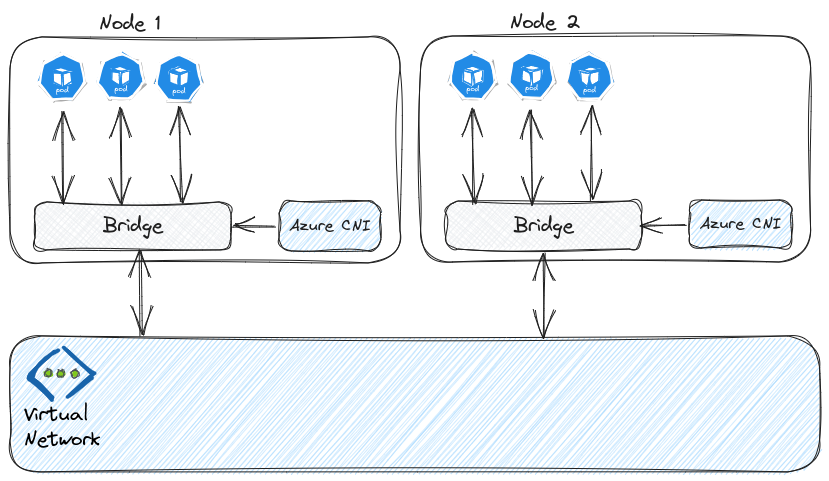
Instead of NAT, Azure CNI creates a bridge for the Pod to be directly visible inside the Vnet. There is no NAT so no additional hop, which means performance similar to VM to VM communication. It’ also possible to have Windows node pools or virtual nodes.
On the less good, we have to plan the virtual network range, since the pods will consume IPs also. As described in the documentation, we need to plan for the upgrade time when new nodes are created. Also, the max number of pods per node has to be taken into consideration. For an Azure CNI cluster, the default value is 30 pods per nodes.
The formula (number of nodes + 1) + ((number of nodes + 1) * maximum pods per node that you configure) from the documentation can be used to plan the requirement in terms of network range on the subnet hosting the cluster.
However, this formula does not take into account the maxSurge parameter which define how many nodes are created at the upgrade time. If the maxSurge is indeed configured to 1, then the formula is valid. If on the other we have a max surge configured to 33% with a 9 nodes cluster, then we would create 3 nodes for the upgrade.
So the formula would become something like (number of nodes + Additional nodes configured for upgrade) + ((number of nodes + Additional nodes configured for upgrade) * maximum pods per node that you configure). Pushing this exemple to the end with the 9 nodes cluster and 30 pods per nodes would gives us a requirement for (9+3)+ (9+3) * 30 meaning 279 IPs.
That’s a lot of IP for a not so big cluster.
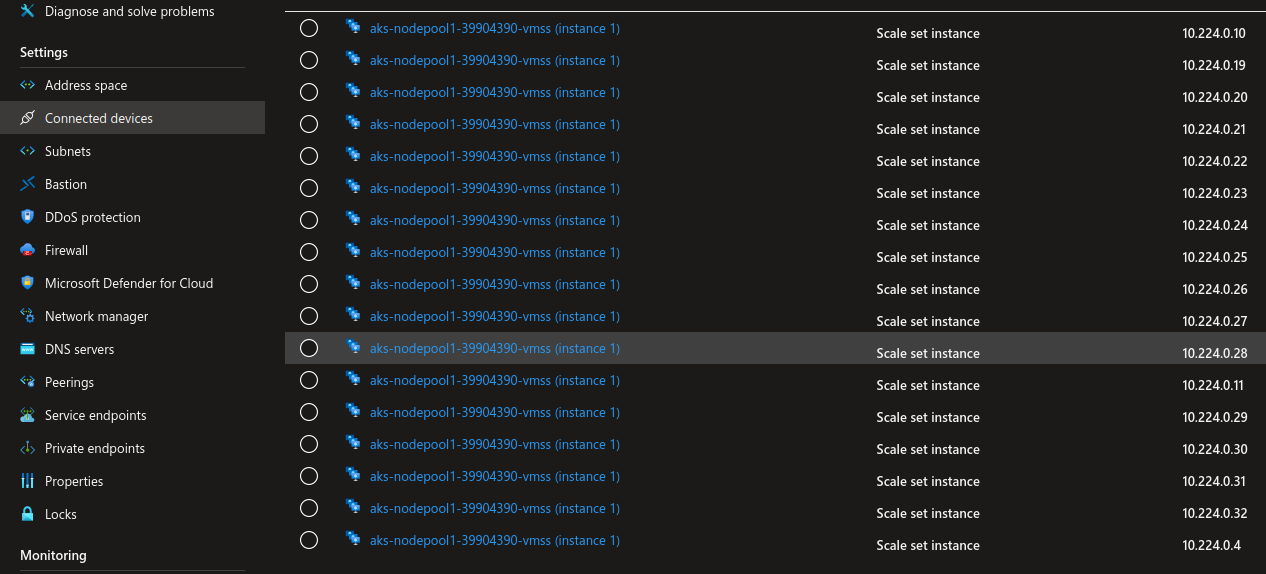
We can see that the cluster reserves the IP in the Vnet if we check the connected device:
There’s an option to optimize the network IP exhaustion describe in the documentation. This is called Azure CNI with dynamic IP allocation. In this case the pods are using another subnet than the nodes. Subnets should be created before the cluster. And afteward, the pods subnet appears as a delegated subnet
yumemaru@azure:~$ az network vnet create -n aks-vnet2 -g aksntwdemo
{
"newVNet": {
"addressSpace": {
"addressPrefixes": [
"10.0.0.0/16"
]
},
"enableDdosProtection": false,
"etag": "W/\"e8b27507-8277-4c4f-8488-5d75153d6de3\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet2",
"location": "eastus",
"name": "aks-vnet2",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"resourceGuid": "3d7afbe5-5605-4411-9f60-749d0dc85aaf",
"subnets": [],
"type": "Microsoft.Network/virtualNetworks",
"virtualNetworkPeerings": []
}
}
yumemaru@azure:~$ az network vnet subnet create -n subnet-aks -g aksntwdemo --address-prefixes 10.0.0.0/24 --vnet-name aks-vnet2
{
"addressPrefix": "10.0.0.0/24",
"delegations": [],
"etag": "W/\"9c35d528-88ff-427c-b95a-771b915210f0\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet2/subnets/subnet-aks",
"name": "subnet-aks",
"privateEndpointNetworkPolicies": "Disabled",
"privateLinkServiceNetworkPolicies": "Enabled",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"type": "Microsoft.Network/virtualNetworks/subnets"
}
yumemaru@azure:~$ az network vnet subnet create -n subnet-pods -g aksntwdemo --address-prefixes 10.0.2.0/23 --vnet-name aks-vnet2
{
"addressPrefix": "10.0.2.0/23",
"delegations": [],
"etag": "W/\"51ede150-fe87-4228-b766-4b51ff810949\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet2/subnets/subnet-pods",
"name": "subnet-pods",
"privateEndpointNetworkPolicies": "Disabled",
"privateLinkServiceNetworkPolicies": "Enabled",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"type": "Microsoft.Network/virtualNetworks/subnets"
}
yumemaru@azure:~$ az aks create -n aks-ntwdemo10 -g aksntwdemo --vnet-subnet-id /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet2/subnets/subnet-aks --pod-subnet-id /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet2/subnets/subnet-pods --network-plugin azure --service-cidr 10.1.0.0/16 --dns-service-ip 10.1.0.10
yumemaru@azure:~$ az network vnet subnet show --vnet-name aks-vnet2 --name subnet-pods -g aksntwdemo | jq .delegations
[
{
"actions": [
"Microsoft.Network/virtualNetworks/subnets/join/action"
],
"etag": "W/\"acadaa68-1a02-4481-aae7-08d468a6ddd3\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet2/subnets/subnet-pods/delegations/aks-delegation",
"name": "aks-delegation",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"serviceName": "Microsoft.ContainerService/managedClusters",
"type": "Microsoft.Network/virtualNetworks/subnets/delegations"
}
]
Still, a overlay would be good, so are there options available?
1.3. Azure CNI with overlay
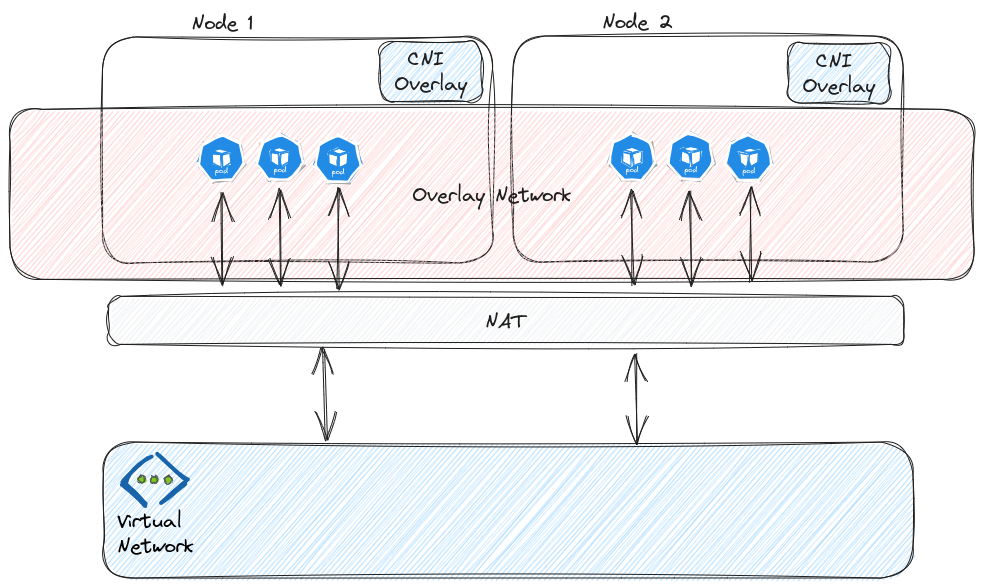
That’s the part that i prefer with AKS, the product team really seems to follow Microsoft clients need. There is now a possibility to avoid IP exhaustion with Azure CNI with overlay. This is kind of a doped kubenet. We could say that the idea is to get the best of both Azure CNI and Kubebet. The documentation described that each node gets assigned a /24 CIDR, much like in kubenet. But there are less limitations, such as more nodes (1000 vs 400), performance on par with Azure CNI and no need for UDRs, and compatibility with both Windows and Linux nodes. Because the overlay traffic isn’t encapsulated, we need to beware of NSG filtering on the subnet, which must allow traffic as follow, in addition to egress traffic requirements:
- Traffic from the node CIDR to the node CIDR on all ports and protocols
- Traffic from the node CIDR to the pod CIDR on all ports and protocols (required for service traffic routing)
- Traffic from the pod CIDR to the pod CIDR on all ports and protocols (required for pod to pod and pod to service traffic, including DNS)
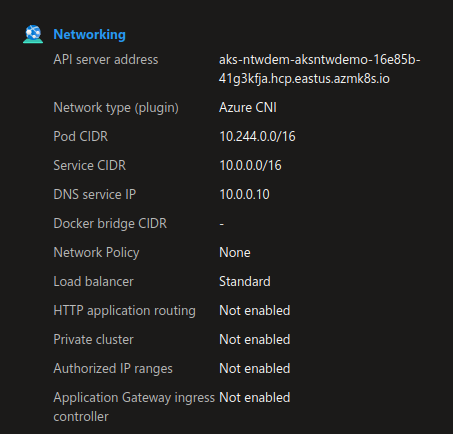
A cluster with Azure CNI overlay will display Azure CNI as a plugin but also a Pod CIDR:
There are some limitation, one to note is the impossibility to use Application Gateway as Ingress Controller. We’ll keep in mind that but since AGIC is evolving for a Gateway API option, there’s a chance that it will also evolve in the near future. We’ll also note the fact that the dual stack ipv4 ipv6 is not available while it is for kubenet or Azure CNI.
1.4. Azure CNI powered by Cilium
Another kind of doped kubenet is Azure CNI powered by Cilium. It is supposed to combines Azure CNI overlay with a data plane management powered by Cilium. It’s interesting because it provides the option to have some of Cilium option without having to manage the Cilium installation and updates.
From a cluster point of view, we don’t get to see a lot of differences. However checking the pods in kube-system, we can see a deployment refering to Cilium.
yumemaru@azure:~$ k describe deployments.apps -n kube-system cilium-operator
Name: cilium-operator
Namespace: kube-system
CreationTimestamp: Tue, 24 Oct 2023 16:24:02 +0200
Labels: app.kubernetes.io/managed-by=Helm
helm.toolkit.fluxcd.io/name=cilium-adapter-helmrelease
helm.toolkit.fluxcd.io/namespace=6537d1ecd4ba270001ceae9f
io.cilium/app=operator
kubernetes.azure.com/managedby=aks
name=cilium-operator
Annotations: deployment.kubernetes.io/revision: 1
meta.helm.sh/release-name: cilium
meta.helm.sh/release-namespace: kube-system
Selector: io.cilium/app=operator,name=cilium-operator
Replicas: 1 desired | 1 updated | 1 total | 0 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: io.cilium/app=operator
kubernetes.azure.com/ebpf-dataplane=cilium
name=cilium-operator
Annotations: cilium.io/cilium-configmap-checksum: fe30fdc0ca01479274381ba26a5e74a606fbe6a1f46fb095407b94c9281777c2
prometheus.io/port: 9963
prometheus.io/scrape: true
Service Account: cilium-operator
Containers:
cilium-operator:
Image: mcr.microsoft.com/oss/cilium/operator-generic:1.12.10
Port: 9963/TCP
Host Port: 9963/TCP
Command:
cilium-operator-generic
Args:
--config-dir=/tmp/cilium/config-map
--debug=$(CILIUM_DEBUG)
Liveness: http-get http://127.0.0.1:9234/healthz delay=60s timeout=3s period=10s #success=1 #failure=3
Environment:
K8S_NODE_NAME: (v1:spec.nodeName)
CILIUM_K8S_NAMESPACE: (v1:metadata.namespace)
CILIUM_DEBUG: <set to the key 'debug' of config map 'cilium-config'> Optional: true
Mounts:
/tmp/cilium/config-map from cilium-config-path (ro)
Volumes:
cilium-config-path:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: cilium-config
Optional: false
Priority Class Name: system-cluster-critical
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: cilium-operator-8cff7865b (1/1 replicas created)
Events: <none>
There’s a lot to tell about Cilium and this article is long enough already. So we’ll keep it for another time. Let’s have a look at the last option now
1.5. Bring your own CNI
It’s possible to create a cluster without a CNI, by specifying None for the network plugin parameter:
az aks create -n aks-ntwdemo8 -g aksntwdemo -l eastus --enable-managed-identity --node-count 1 --network-plugin none
Checking the nodes, we will see that there are in a NotReady State, waiting to have a CNI deployed:
yumemaru@azure:~$ k get no
NAME STATUS ROLES AGE VERSION
aks-nodepool1-24351847-vmss000001 NotReady agent 140m v1.26.6
We could deploy any CNI with the associated documentation. Again, let’s stop it here for now. Because Cilium has such traction lately, there’s a chance that another article about this will come around anyway.
For now, we’ve seen eveything we had to see regarding the network plugin options. Let’s take a step back andd look at the Virtual NEtwork again.
2. Subnet usage
Up until now, we’ve seen that the nodes live in their own subnet. Depending on the CNI, we may or may not need a bigger range. However there are some case where we can add other subnets. We’ve seen one with the API Server vnet integrated, or the Azure CNI with dynamic IP allocation. In both case we get an additional subnet, configured as delegated for use by AKS.
There are 2 others cases where we can have additional subnets.
The first one is with additional node pools:
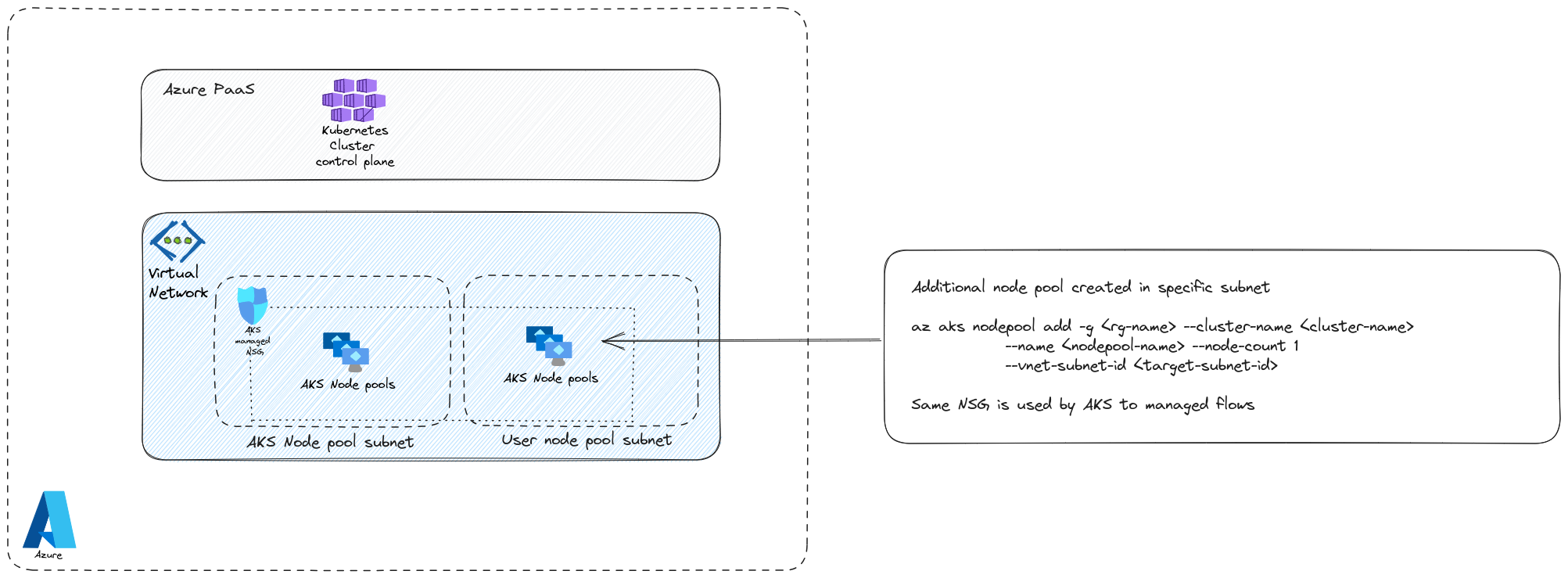
As illustrated, we can specify an additional subnet and add another nodepool pointing to this subnet. A few thing to take into consideration:
- The network cannot be managed by AKS, meaning that we have to prepare the network before the cluster creation, with the required subnet.
- Because AKS manages an NSG on the node pools directly, adding a new subnet for another node pool does not bring network segregation from a filtering point of view. If on the other hand, each subnet has its own NSG, then yes there is additional network segregation.
yumemaru@azure:~$ az network vnet create -n aks-vnet3 -g aksntwdemo --address-prefixes 172.20.0.0/24
{
"newVNet": {
"addressSpace": {
"addressPrefixes": [
"172.20.0.0/24"
]
},
"enableDdosProtection": false,
"etag": "W/\"df04b35c-803d-412d-b0b0-fa045e091b62\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet3",
"location": "eastus",
"name": "aks-vnet3",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"resourceGuid": "94ff2b33-f0dc-4d96-8b86-28cab6baf844",
"subnets": [],
"type": "Microsoft.Network/virtualNetworks",
"virtualNetworkPeerings": []
}
}
yumemaru@azure:~$ az network vnet subnet create -n aks-subnet -g aksntwdemo --vnet-name aks-vnet3 --address-prefixes 172.20.0.0/26
{
"addressPrefix": "172.20.0.0/26",
"delegations": [],
"etag": "W/\"04beae60-ba2f-43bb-8f32-0e4b234d6407\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet3/subnets/aks-subnet",
"name": "aks-subnet",
"privateEndpointNetworkPolicies": "Disabled",
"privateLinkServiceNetworkPolicies": "Enabled",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"type": "Microsoft.Network/virtualNetworks/subnets"
}
yumemaru@azure:~$ az network vnet subnet create -n np-subnet -g aksntwdemo --vnet-name aks-vnet3 --address-prefixes 172.20.0.64/26
{
"addressPrefix": "172.20.0.64/26",
"delegations": [],
"etag": "W/\"beba6d57-5497-4b5c-a910-0b1f02d7e6db\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet3/subnets/np-subnet",
"name": "np-subnet",
"privateEndpointNetworkPolicies": "Disabled",
"privateLinkServiceNetworkPolicies": "Enabled",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"type": "Microsoft.Network/virtualNetworks/subnets"
}
yumemaru@azure:~$ az aks create -n aks-ntwdemo12 -g aksntwdemo --vnet-subnet-id /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet3/subnets/aks-subnet --network-plugin kubenet
After that we can add a node pool and specify the subnet:
yumemaru@azure:~$ az aks nodepool add --cluster-name aks-ntwdemo12 -g aksntwdemo -n aksnp02 --vnet-subnet-id /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet3/subnets/np-subnet --node-count 1
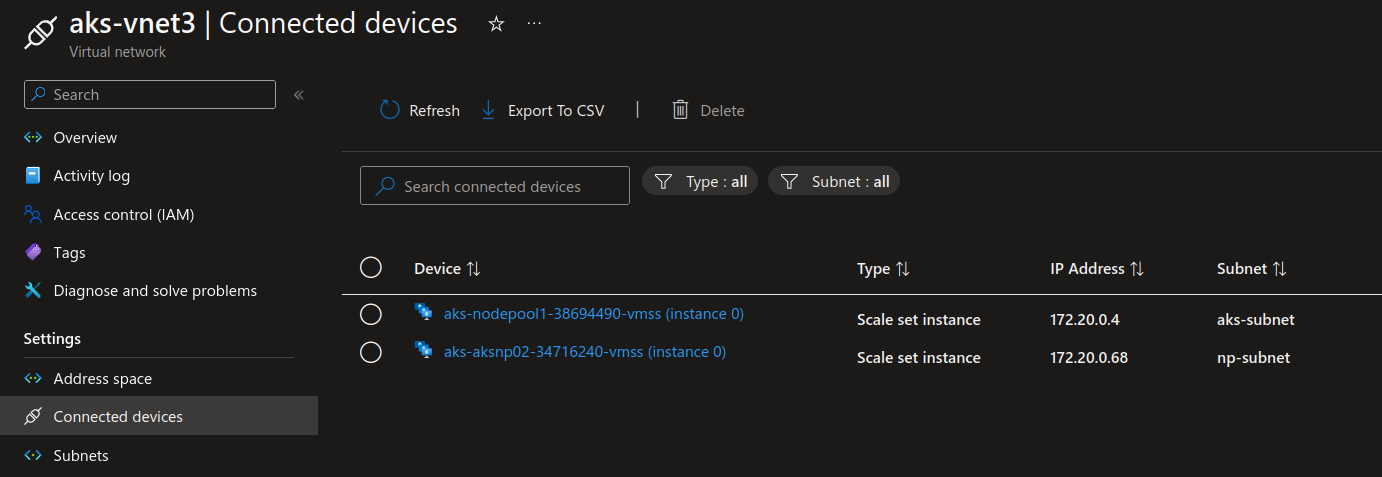
Looking at the connected devices in the vnet, we do see the node pools in different subnets:
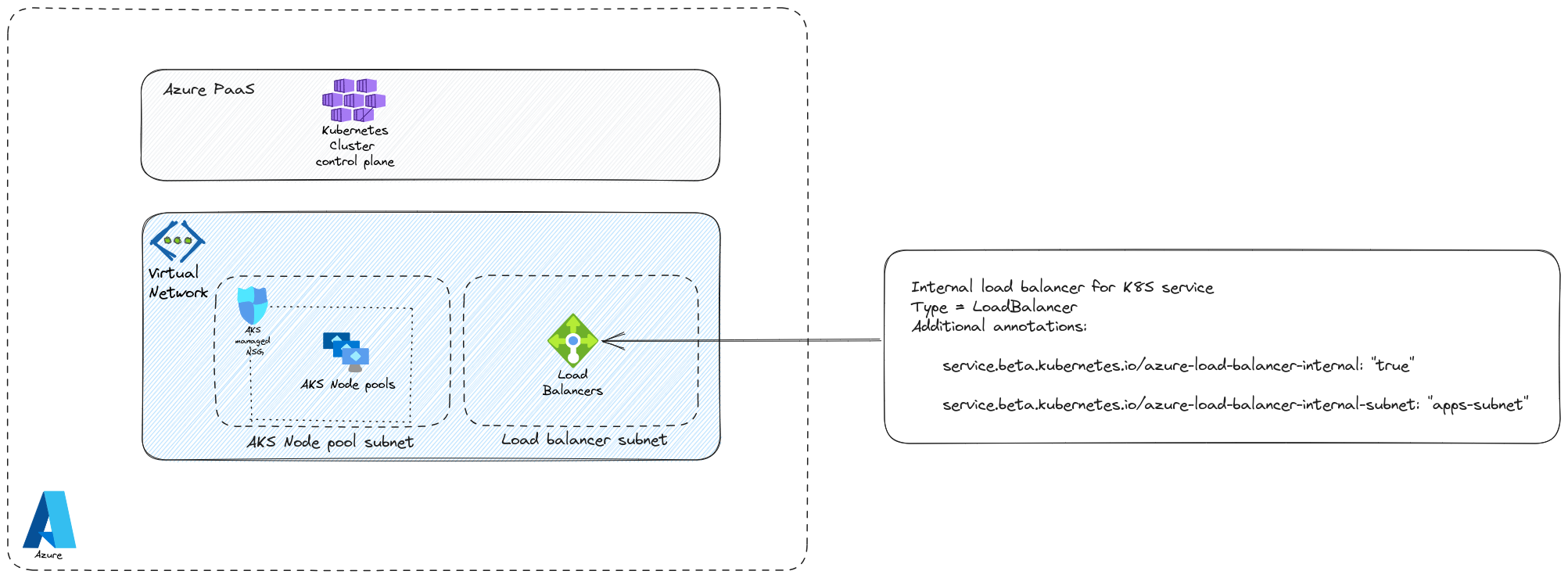
Last, we can also have a dedicated subnet for the Internal load balancer that we use for K8S services. This is more on the Kubernetes control plane, but it does reflect in the Azure plane so let’s take a few lines to discuss this.
Let’s create a deployment:
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: testns
spec: {}
status: {}
---
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: testdeploy
name: testdeploy
namespace: testns
spec:
replicas: 3
selector:
matchLabels:
app: testdeploy
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: testdeploy
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
As mentionned, we want to use another subnet for the Internal Load Balancer:
yumemaru@azure:~$ az network vnet subnet create -n ilb-subnet -g aksntwdemo --vnet-name aks-vnet3 --address-prefixes 172.20.0.128/26
{
"addressPrefix": "172.20.0.128/26",
"delegations": [],
"etag": "W/\"d029c31e-9fde-441e-808d-b72b246dc617\"",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/aksntwdemo/providers/Microsoft.Network/virtualNetworks/aks-vnet3/subnets/ilb-subnet",
"name": "ilb-subnet",
"privateEndpointNetworkPolicies": "Disabled",
"privateLinkServiceNetworkPolicies": "Enabled",
"provisioningState": "Succeeded",
"resourceGroup": "aksntwdemo",
"type": "Microsoft.Network/virtualNetworks/subnets"
Now let’s create the service on the Kubernetes side. We’ll note the 2 annotations, service.beta.kubernetes.io/azure-load-balancer-internal to use an internal load balancer and service.beta.kubernetes.io/azure-load-balancer-internal-subnet to target the specific subnet:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-internal: "true"
service.beta.kubernetes.io/azure-load-balancer-internal-subnet: "ilb-subnet"
labels:
app: testdeploy
name: testdeploy
namespace: testns
spec:
type: LoadBalancer
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: testdeploy
Upon creation, we should see the service on the kubernetes side with a private IP from the subnet:
yumemaru@azure:~$ k get svc -n testns
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
testdeploy LoadBalancer 10.0.175.119 172.20.0.132 80:32709/TCP 44s
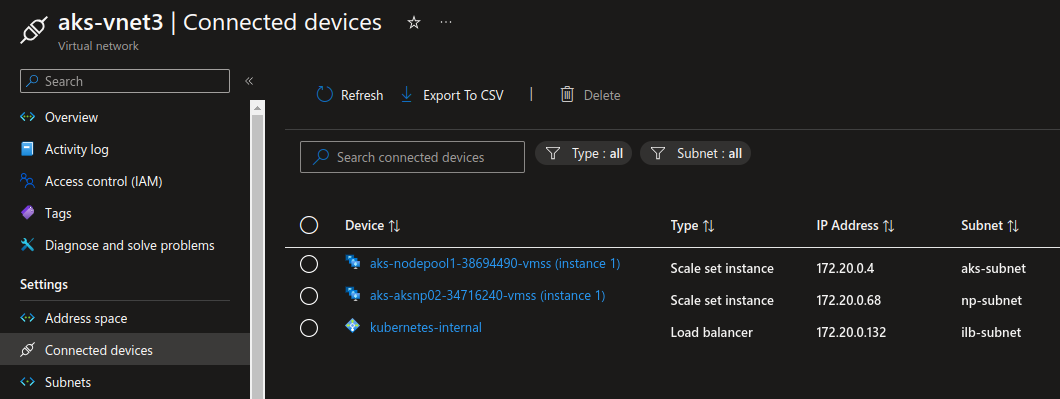
And the corresponding internal load balancer in the subnet:
We’re finished with the subnet usage.
That will be all. Let’s wrap it
3. Before leaving
We’ve seen a lot on this 2 part article. Let’s summarize a bit:
| Area | Actions |
|---|---|
| Control plane | Protect API server access with either </br> - Accept list </br> - Private clusters </br> - API Server Vnet integration |
| Worker plane | Configure nodes and pods networking </br> - with kubenet, which isolate nodes IP range in Vnet from pods IP range on overlay </br> - with Azure CNI which uses Vnet range for both pods and nodes </br>Get the better of both world with Azure CNI with overlay or Azure CNI powerered by Cilium </br>Take full control of your kubernetes network with BYO CNI |
| Subnet usage | Use additional subnets on the Azure plane for </br> - Additional Node pools </br> - Internal Load balancers </br> - Pods in Azure CNI with dynamic allocation </br> - The API server with the integrated option |
We did not take time to talk about this but we should also plan for the egress traffic for AKS. By design, it needs some flows that are detailed in a specific section of the documentation. We can either configure filtering through NSG rules or through Azure Firewall.
Now I’ll probably come back on AKS with BYO CNI, specifically because I want to dig a bit on Cilium.
Until now, have fun ^^