Sandbox containers and AKS
Hello All!
In this article, I would like to talk about sandbox container, in Azure Kubernetes Service context.
We will start by introducing the concepts behind sandbox container, why it may be needed. Then we’ll look at the currently available solution onr sandbox container in Kubernetes. And last, we’ll go pragmatics and demonstrate how the sandbox container tehnologies are deployed and used in an AKS cluster.
1. Container sandboxing 101
Before understanding the need of sandbox containers, we need to step back a little and look at the basics of container architecture.
Remember, the idea behind container is to have a lighter abastraction layer btween the app and its hosts. In the virtualization world, we have the host, the hypervisor, and the virtual machine which then host the app binary.
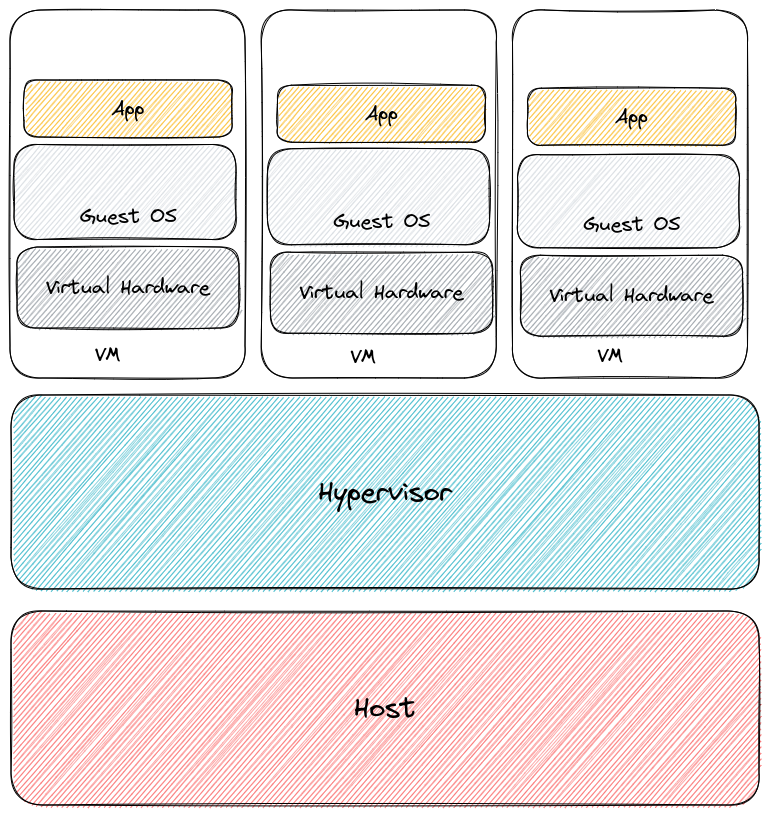
In the container world, the hypervisor disappears, along with the Virtual Machine layer and its OS.
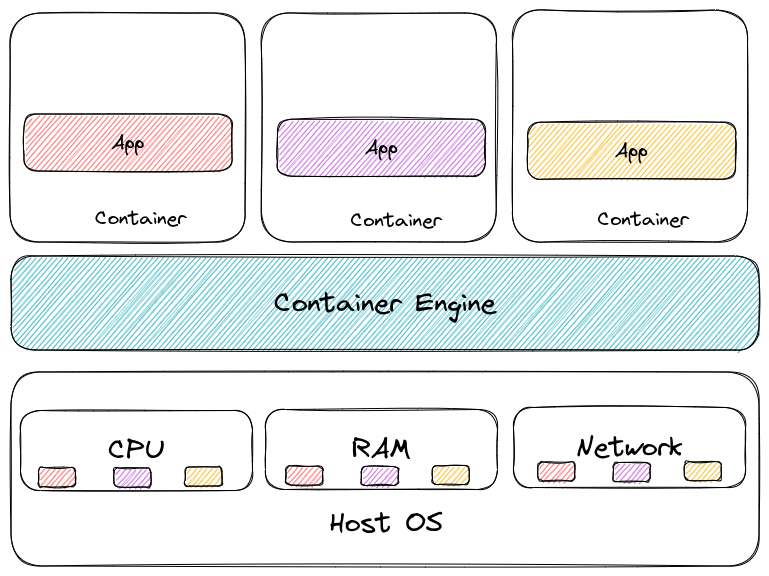
The result is what everyone knows, it’s way more fast and resource efficient to have those layers removed and depends only on the container engine and the kernel capabilities to isolate workloads.
However, because there is so much less layer, there is also less isolation. The kernel is shared, even if there is isolation by the mean of cgroups and namespace.
Because there are some case where a better isolation is needed, technical solutions were developped. Those solutions are usually based on one of the 2:
- Rule-based execution
- Machine level virtualization
Rule-based execution is used by identifying which syscall are made by the app, and by allowing only those calls from the container to the shared host kernel. Solutions using Rule-based execution are seccomp, SELinux or AppArmor.
Machine level virtualization is probably easier because it provides an isolation through a light-weight virtual machine.
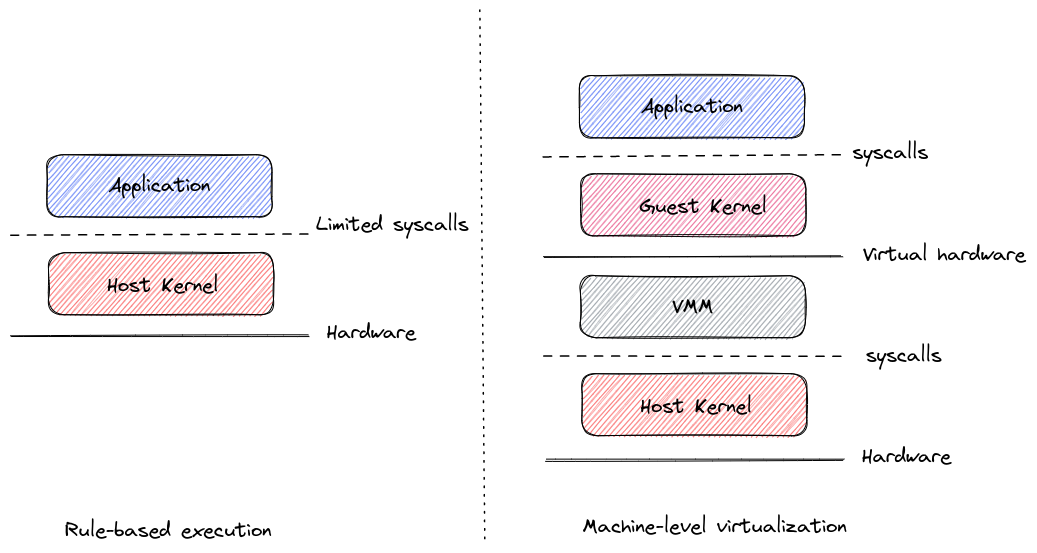
While Machine level virtualization relies on light-weight virtual machine, it does impact the performance of the application that is hosted in this sandboxed container.
In the Machine level virtualization category, we find katacontainer, on which we will have a look at in the following part.
To conclude with the sandbox container solutions, we should have a look at gVisor. gVisor acts as an intermediary between the application and the host kernel. It intercepts the syscall from the application and pass only limited calls to the host kernel.
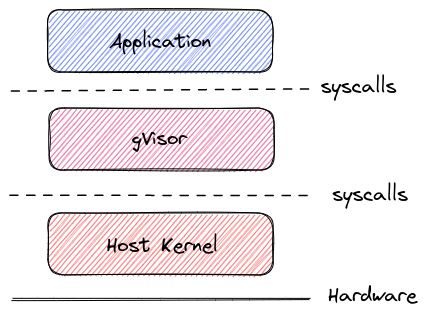
Ok that’s all for the intro on sandbox containers. In the following sections, we will let the Rule-based execution apart and focus more specifically on katacontainer and gVisor, in an AKS context.
2. Preparing for sandbox containers in AKS
Let’s go back to our cloud managed Kubernetes now. If we look at either gVisor or katacontainer, there are things to install on the kubernetes nodes. Except that, well, we usually don’t install anything on the nodes. Indeed, those nodes are actually instances from vm scale sets. By design, the scale sets are managed by the control plane of AKS, and the instances lifecycle is not managed by a human admin. Because of this, it is not really practicle to install any binary on a node each time it is provisioned.
There’s a way, though, to have a pod running on each nodes. For use case like that, we can rely on the daemonset controller, which will ensure that we have the pods described in the controller always deployed on each nodes of our cluster.
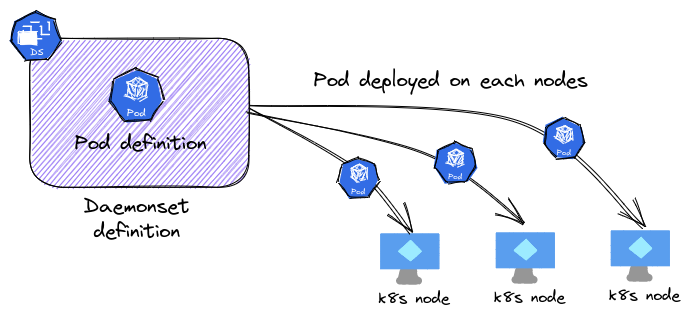
If we consider an AKS cluster, we can use daemon sets along with taints on node pools to have pods running on each sets of nodes in a node pools.
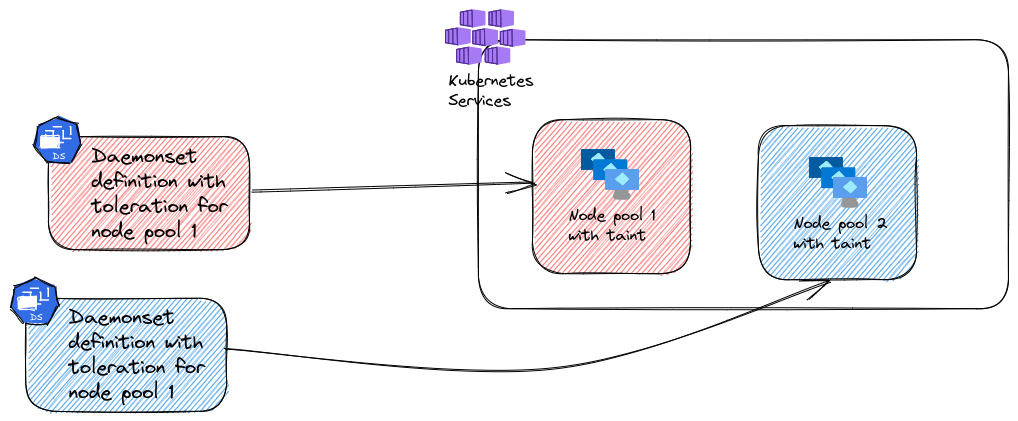
If we want to install gVisor (or any binary as a matter of fact) on all the nodes of a specific node pool, we could rely on a daemonset which would deploy a pod with an elevated container. If this said container was configured to execute the installation of gVisor, then we could achieve our goal.
There are a few watch points here however:
- First, we need to have a pod with elevated access, in this case access to the node local storage at least, so that we could deploy sandboxed container. There may be a contradiction here, don’t you think?
- Second, we need to modify the configuration of nodes managed by an Azure service. So while the approach wit the daemonset is typical of kubernetes environment and thus respect the best practice of kubernetes node management, it is kind of a grey zone in terms of Azure support. Meaning it should work but if it does not anymore, we’re on our own because there won’t be any support from Microsoft, or at least, not that much.
There’s an excellent article detailing this configuration, written by Daniel Neumann on his blog which details the configuration of said container and how to deploy It with a daemonset. We’ll reviw that a bit in the next section of this article.
Another way for sandbox container, this time supported by Microsoft, is to rely on a sandbox technology available on the underlying OS of the node image. Luckily for us, this is the case for katacontainer and the node image based on Mariner. In this specific case, no installation on the nodes is required, and we can only focus on the kubernetes part of creating our sandbox container.
If we dive a little deeper on our AKS architecture, we should remebmer that by default we have 1 node pool (a.k.a the default node pool). This node pool is by default (for now at least) an Ubuntu based node pool so no katacontainer there. Also, because it’s the default system node pool, it hosts all the AKS required pods for AKS to work. It’s better to leave it alone, so we’ll use additional node pool.
Regarding gvisor, it can be any node pool because this is self-managed sandbox software install, so there is no underlying architecture requirement. Adding a node pool is not too difficult and can be done from the portal, az cli or some terraform configuration.
For katacontainer, we do have a requirement to use a Mariner node pool.
It’s important to remember that it is currently a preview, and as such it requires to be activate in the provider with the command az feature register command.
az feature register --namespace "Microsoft.ContainerService" --name "KataVMIsolationPreview"
Also, we have to specify the --workload-runtime to KataMshvVmIsolation so that the feature is activated on the node pool. Otherwise, the runtime class will not be available. More on that in the next part.
az aks nodepool add --cluster-name <AKS_Cluster_Name> --resource-group <AKS_Resource_Group> --name <Node_Pool_Name> --os-sku mariner --workload-runtime KataMshvVmIsolation --node-vm-size <VM_Size>
Interestingly enough, while there is a workload_runtime parameter in the terraform provider, it currently only support OCIContainer or WasmWasi. So we are stuck with either az cli or ARM (or bicep).
That’s almost all on the node pool configuration. The last details are more in the kubernetes plane so we will have a look in the next part
3. Running Sandbox container in AKS with gvisor
first thing first, let’s have a look on our nodes. With a custom columns selection, we can get the taints and labels. Note that we’re selecting a specific label here:
yumemaru@azure$ k get nodes -o custom-columns='NodeName:.metadata.name,LabelAgentPool:.metadata.labels.agentpool,NodeTaintsKey:.spec.taints[].key,NodeTaintsValue:.spec.taints[].value,NodeTaintsEffect:.spec.taints[].effect'
NodeName LabelAgentPool NodeTaintsKey NodeTaintsValue NodeTaintsEffect
aks-aksnp0sbxcon-29325118-vmss00000p aksnp0sbxcon CriticalAddonsOnly true NoSchedule
aks-aksnp0sbxcon-29325118-vmss00000q aksnp0sbxcon CriticalAddonsOnly true NoSchedule
aks-aksnp0sbxcon-29325118-vmss00000r aksnp0sbxcon CriticalAddonsOnly true NoSchedule
aks-npgvisor-28185204-vmss00000b npgvisor gvisor true NoSchedule
aks-npgvisor-28185204-vmss00000c npgvisor gvisor true NoSchedule
aks-npkata-37278511-vmss000006 npkata KataContainer true NoSchedule
aks-npkata-37278511-vmss000007 npkata KataContainer true NoSchedule
aks-npkata-37278511-vmss000008 npkata KataContainer true NoSchedule
yumemaru@azure$
With that, we can install gvisor with a daemonset:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: gvisor
namespace: kube-system
spec:
selector:
matchLabels:
app: gvisor
template:
metadata:
labels:
app: gvisor
spec:
hostPID: true
restartPolicy: Always
containers:
- image: docker.io/yumemaru1979/gvisor:latest
imagePullPolicy: Always
name: gvisor
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
privileged: true
readOnlyRootFilesystem: true
volumeMounts:
- name: k8s-node
mountPath: /k8s-node
volumes:
- name: k8s-node
hostPath:
path: /tmp/gvisor
tolerations:
- key: gvisor
operator: Exists
effect: NoSchedule
nodeSelector:
agentpool: npgvisor
The interesting part on a scheduling point of view here is the toleration which match the one from our node gvisor gvisor=true:NoSchedule.
We are also using a nodeSelector to match the agentpool: npgvisor so that we are sure that the pods will only execute on this node pool.
For the image and what it does, really, I took the information from Daniel Neumann blog as mentionned earlier.
To summarize, installing gvisor requires adding runsc on the node, and modifying containerd accordingly. The gvisor documentation details this in the installation section.
When the daemonset is scheduled, we should see something like that:
yumemaru@azure$ k get daemonsets.apps gvisor -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
gvisor 2 2 2 2 2 agentpool=npgvisor 34h
Checking on the portal, we can also see which pod run on which node:
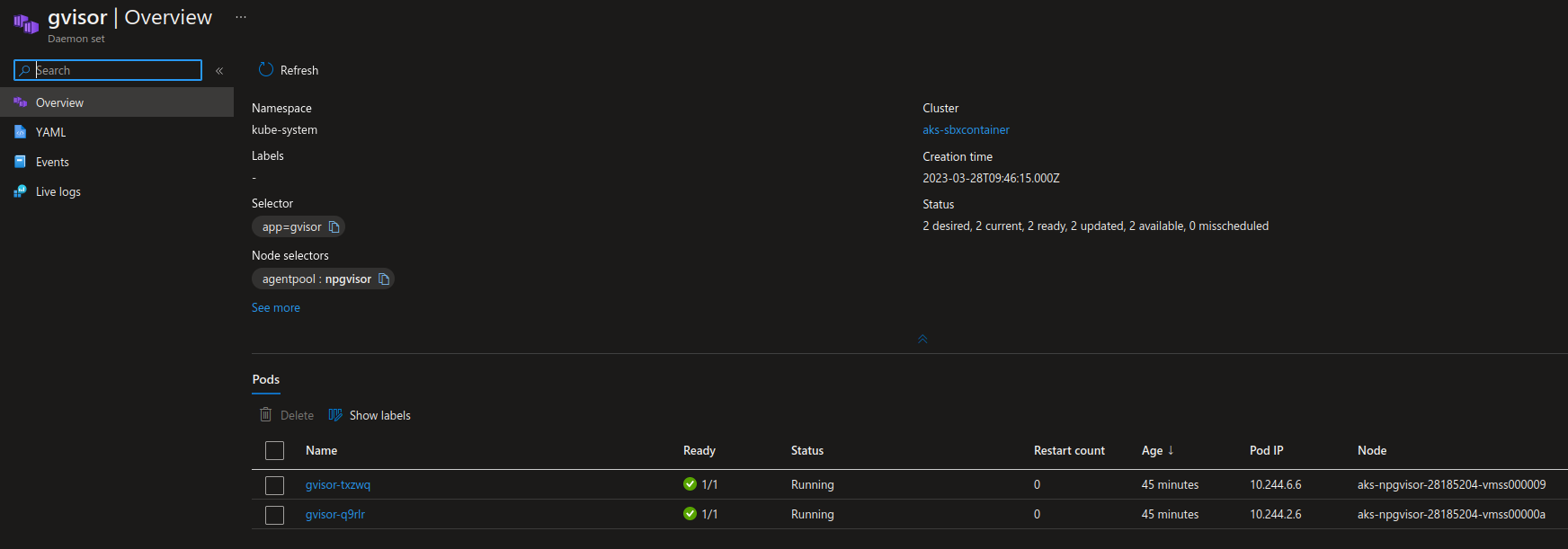
With that ready, we need now to add a runtime class:
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: gvisor
handler: runsc
scheduling:
nodeSelector:
agentpool: npgvisor
And last, we can schedule pods on the node pool. To use the runtime class and thus get a sandboxed container, we need to specify the runtimeClassName. We also specify the NodeSelector and the tolerations to ensure that the pod can run on the node pool that we want:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: gvisor
name: gvisortest
namespace: gvisordemo
spec:
runtimeClassName: gvisor
nodeSelector:
agentpool: npgvisor
tolerations:
- key: gvisor
operator: Exists
effect: NoSchedule
containers:
- image: nginx
name: gvisortest
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
For comparison purpose, we can also add a not sandboxed pod:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: test
name: test
namespace: gvisordemo
spec:
tolerations:
- key: gvisor
operator: Exists
effect: NoSchedule
containers:
- image: nginx
name: test
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Checking the pod kernel version gives us 2 differents versions:
yumemaru@azure$ k exec -n gvisordemo test -- uname -r
5.4.0-1103-azure
yumemaru@azure$ k exec -n gvisordemo gvisortest -- uname -r
4.4.0
Any other pod with the standard ubuntu node should have the same kernel version:
yumemaru@azure$ k exec -n kube-system gvisor-nczx6 -- uname -r
5.4.0-1103-azure
And that’s it for gvisor sandbox container. Easyonce we have tackled the gvisor install, which is not so easy on AKS node. Let’s move to katacontainer now.
4. sanbox with katacontainer
With katacontainer, it’s way more managed. Since the Mariner nodes are already compatible with this sandbox technology, we just have to schedule a pod with the appropriate runtimclass.
To be sure to get the appropriate one, we can use the following command:
yumemaru@azure$ k get runtimeclasses.node.k8s.io
NAME HANDLER AGE
gvisor runsc 13s
kata-mshv-vm-isolation kata 11d
runc runc 11d
The one that we want is kata-mshv-vm-isolation
apiVersion: node.k8s.io/v1
handler: kata
kind: RuntimeClass
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"node.k8s.io/v1","handler":"kata","kind":"RuntimeClass","metadata":{"annotations":{},"labels":{"addonmanager.kubernetes.io/mode":"Reconcile","kubernetes.io/cluster-service":"true"},"name":"kata-mshv-vm-isolation"},"scheduling":{"nodeSelector":{"kubernetes.azure.com/kata-mshv-vm-isolation":"true"}}}
creationTimestamp: "2023-03-18T21:15:46Z"
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kata-mshv-vm-isolation
resourceVersion: "554541"
uid: a18f3303-4af5-4d6e-95f4-9e492c1c94a7
scheduling:
nodeSelector:
kubernetes.azure.com/kata-mshv-vm-isolation: "true"
Now we can prepare a pod to use this runtime:
apiVersion: v1
kind: Pod
metadata:
labels:
run: katatest
name: katatest
namespace: katademo
spec:
nodeSelector:
agentpool: npkata
runtimeClassName: kata-mshv-vm-isolation
tolerations:
- key: KataContainer
operator: Exists
effect: NoSchedule
containers:
- image: nginx
name: katatest
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
And again create another one with the default runc runtimeclass:
apiVersion: v1
kind: Pod
metadata:
labels:
run: katatest
name: test2
namespace: katademo
spec:
nodeSelector:
agentpool: npkata
tolerations:
- key: KataContainer
operator: Exists
effect: NoSchedule
containers:
- image: nginx
name: katatest
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
If we check the kernel of those 2 pods, we can see different version for the kernel, while all other pods (on this node pool) have the same version:
yumemaru@azure$ k exec -n katademo katatest -- uname -r
5.15.48.1-9.cm2
yumemaru@azure$ k exec -n katademo test2 -- uname -r
5.15.92.mshv1-hvl1.m2
yumemaru@azure$ k exec -n katademo test3 -- uname -r
5.15.92.mshv1-hvl1.m2
And with that we are finished.
5. To conclude
So the good news is that sandbox containers are now officially supported thanks to the katacontainer support on Mariner nodes. The manual install through a daemonset is still possible but not supported from an Azure plane point of view.
Note that for now, there are some limitation with sandbox container with katacontainer, notably no support for CSI drivers.
That will be all for today. See you soon!